方法
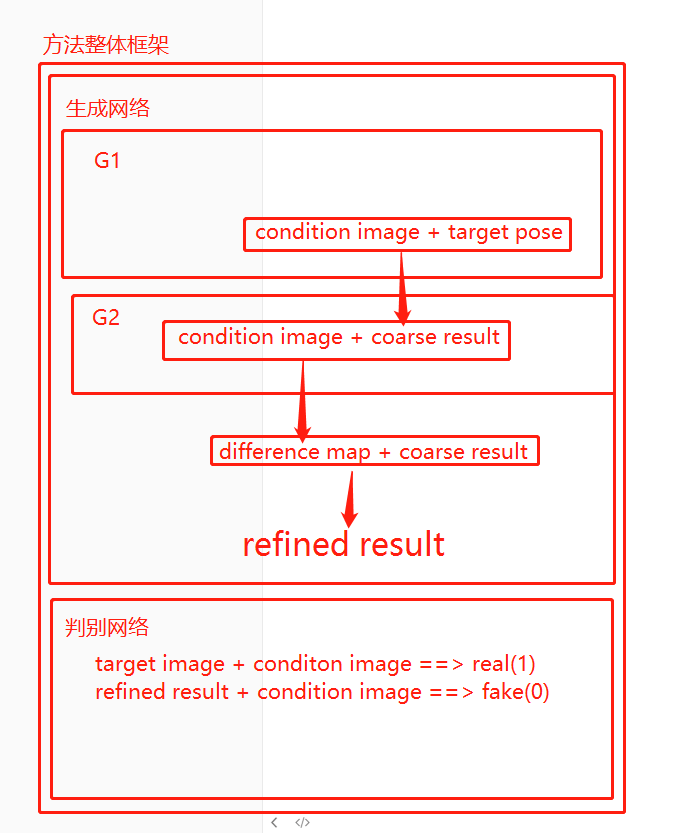
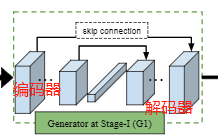
有两个阶段,对于第一阶段,提出并分析几个几个模型以及变体,第二阶段,使用附加条件的深度卷积对抗生成网络(DCGAN)的变体来填充更多外观细节。 PG2的总体框架如图所示 :
步骤一,姿势集成
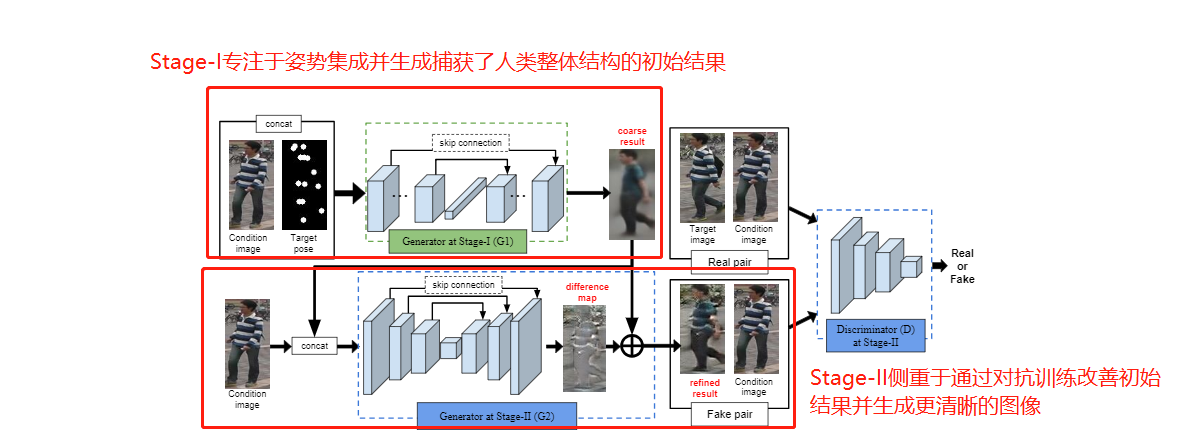
在阶段一,将一个筛选过的人的图像(condition person image) IA与一个目标姿势(target post)PB整合在一起,生成一个粗糙结构(coarse result)IB,该结构大致描述了IB中的人体整体结构。
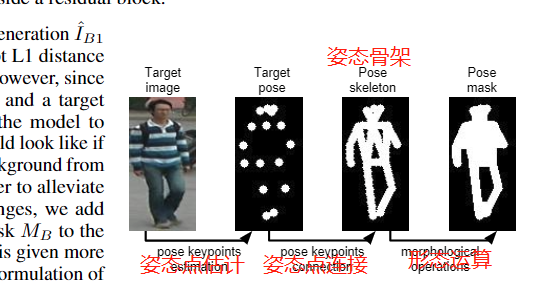
姿态嵌入。将target image和condition image输入,模型干的事:生成有关键点的target pose,然后连接起来,再通过形态运算得出pose mask。
采用最先进的姿态估计器(Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh. Realtime multi-person 2d pose estimation using part affinity fields.arXiv, 1611.08050, 2016.)来获得近似人体姿态:姿态估计器生成18个关键点的坐标,这些坐标输入到模型中,模型学习将每个关键点映射到人体上的对应位置上。这样,就将PB编码为有18个热力点的图。每一个热力点在对应的关键点附近(半径为4像素的圆)填充了1,而在其他地方都是0。
![1532320546222]()
我的理解是,目标点通过上述的姿态估计器生成关键点,然后连接这些关键点成骨架,再通过形态算法的之类的方法,将骨架变成Target Pose Mask。
生成网络G1。把IA和PB串联起来输入到模型中,然后使用卷积层来整合这两种信息。这个卷积层由两部分组成:编码器和解码器,中间有一个叫跳跃连接的东西,将图像信息从input传向output。
采用U-Net-like结构(Tran Minh Quan, David G. C. Hildebrand, and Won-Ki Jeong. Fusionnet: A deep fully residual convolu-tional neural network for image segmentation in connectomics. arXiv, 1612.05360, 2016.),也就是具有跳跃连接的卷积自动编码器。
![1532323894576]()
首先使用了几个堆叠卷积层,从小的局部邻域到更大的区域,整个IA和PB两个图像。这样,外观信息被整合后并传输到相邻的身体部分。
然后,使用完全连接的网络层,使得远程身体部位之间的信息也可以交换。
之后,解码器和其对应的编码器产生图像,该解码器由与编码器对称的堆叠卷积层组成。与编码器对称的堆叠卷积层组成一个解码器。
这个图像叫做B1,在U-Net中,编码器和解码器之间的Skip connetciton能将图像信息直接从input传导output。论文中建议简化原始残差块(Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, pages 770–778, 2016.)和建议只留两个连续的卷积激活函数在残差块(consecutive conv-relu )就好了。
Pose mask的损失函数阶段1用的损失函数是L1,主要将背景的权重降低。
网络模型中采用L1损失函数(采用L1距离作为阶段的生成损失) ==> 为了比较B1和IB。
MB(pose mask)被设置为前景1和背景0;通过连接人体部分和应用一套形态学操作来计算出MB ==> 使得它能够大致覆盖目标图像中的整个人体。
G1的输出是模糊的,因为L1损失函数的结果是所有可能性的平均值(Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. Image-to-image translation with conditional adversarial networks. In CVPR, 2017.)。然而,G1确实捕获了我们指定的目标姿态的全局结构信息,以及其他低频信息(例如衣服的颜色)。高频信息,姿态的细节,将通过对抗训练在第二阶段细化。
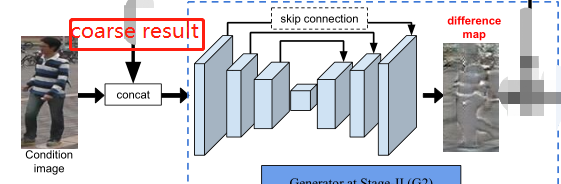
2. 步骤二,图像改进
使用一种卷积生成对抗网络(Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv, 1511.06434, 2015.)(DCGAN)的变体作为基本模型。
生成网络G2
G2目的是生成差分图(an appearance difference map) ==> 使初始结果更接近目标图像
生成an appearance difference map还是用和阶段1相似的U-Net,但是输入是IB和IA(condition image),该U-Net里是没有完全链接层的(the fully-connected layer) ==>这是和阶段1里的U-Net的不同之处 ==> 完全连接层会压缩输入的很多信息,这样子做能保留输入的更多信息
使用different map加速了模型的收敛,因为模型专注于学习丢失的外观细节,而不是从头开始合成目标图像。
![1532351298006]()
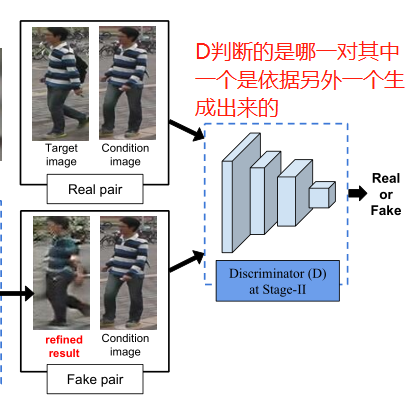
判别网络
G2将IA(condition image)代替噪声输入到GAN中。
让判别网络判断的是(IA, IB)和(`IB2, IA),`IB2是G2的输出 ==> 这种做法能让判别器学习`IB2和IB的区别,IB是阶段1的输出。
该判别网络不必加噪声。
训练GAN过程中,迭代优化D和G2。
3.神经网络架构
在阶段1,G1的编码器由N个残差块和一个完全连接的层组成,其中N取决于输入的大小,每个残差块由两个卷积层组成,其中的步幅为1,紧跟最后一个块的一个子采样卷积层,其步长为2。
在第二阶段,G2的编码器具有完全的卷积结构,包含N-2卷积块,没有完全链接层。
每个块由两个卷积层组成,其中步幅=1,一个子采样卷积层具有步长=2。
G1和G2中的解码器与相应的编码器是对称的。
在G1和G2中,没有应用batch normalization 或者 dropout(dropout是一种规范化技术)。
所有的卷积层由3×3滤波器组成,滤波器的数目与每个块线性增加。
除了完全连接层和输出卷积层之外,每个层都用来一个激活函数Relu。
鉴别器采用了与DCGAN相同的网络结构,除了输入卷积层的大小(因为图像分辨率的不同)。